

Ingest Microsoft SQL Server metadata on Datahub
Datahub is an open-source metadata platform for the modern data stack. We have integrated the SQLFlow into Datahub so that the SQLFlow data lineage is enabled in the Datahub UI. Check this blog for how to integrate SQLFlow into Datahub.
There are three ways to ingest your MySQL metadata to Datahub:
- Datahub UI (v0.10.4 is used in this blog)
- Command Line
- Rest API (Java/Python sdk are available. This approach is ideal for metadata without a fixed format or any other sources not supported by DataHub)
This blog will introduce how to ingest the Microsoft SQL Server metadata to Datahub with the first two approaches.
Prerequisites
Install the following plugins on the Datahub server:
pip3 install 'acryl-datahub[datahub-rest]'
pip3 install 'acryl-datahub[mssql]'Ingest metadata from Datahub UI
a. Click Ingestion on the DataHub menu bar
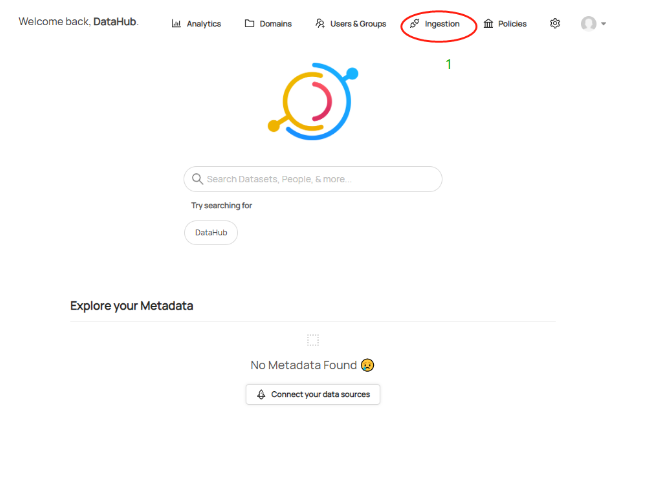
b. Select Sources and click Create new source
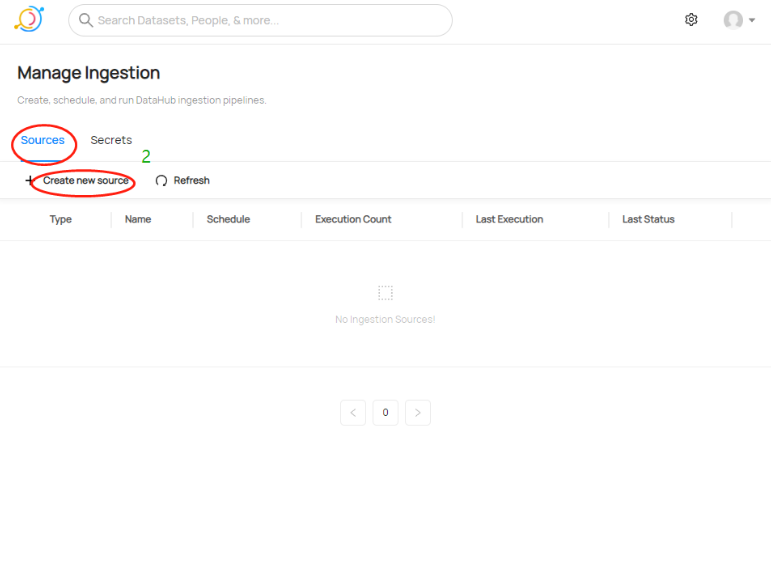
c. Choose Microsoft SQL Server in the source list

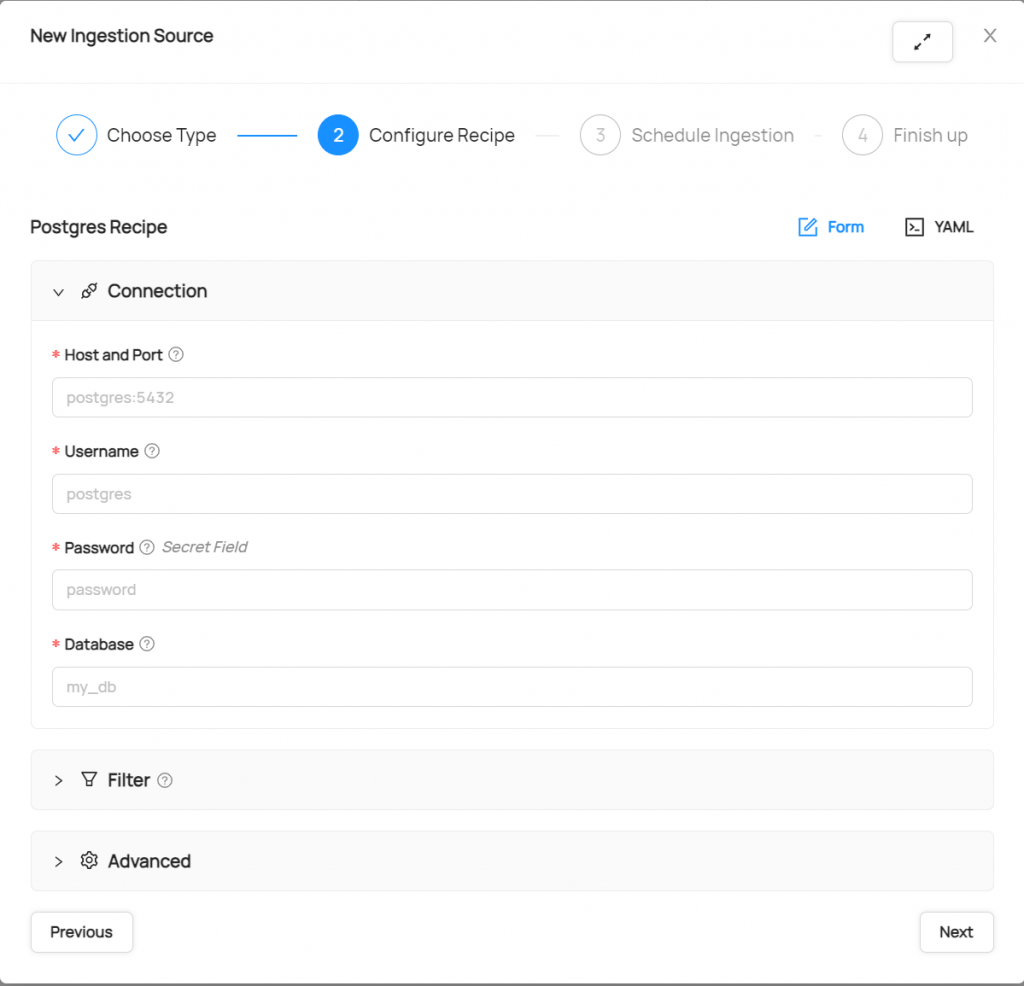
d. Configure the database connection
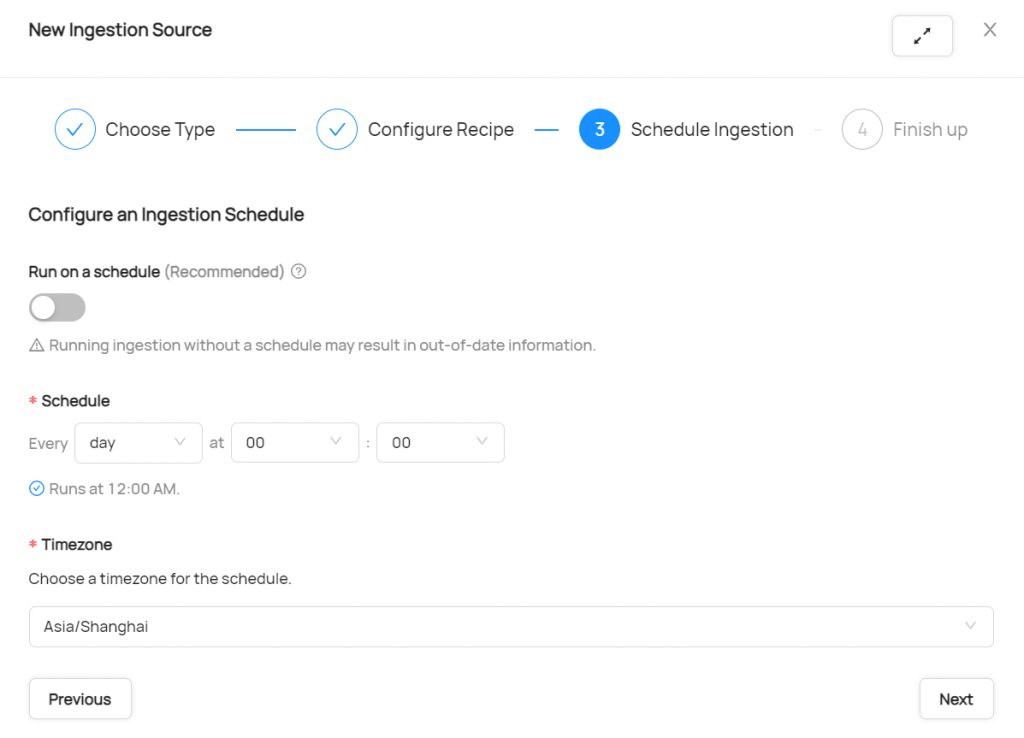
e. Click next to configure the schedule Ingestion. If you need to update metadata periodically, you can configure schedule Ingestion. It can greatly reduce the workload of manual import.
f. Give a name to the source
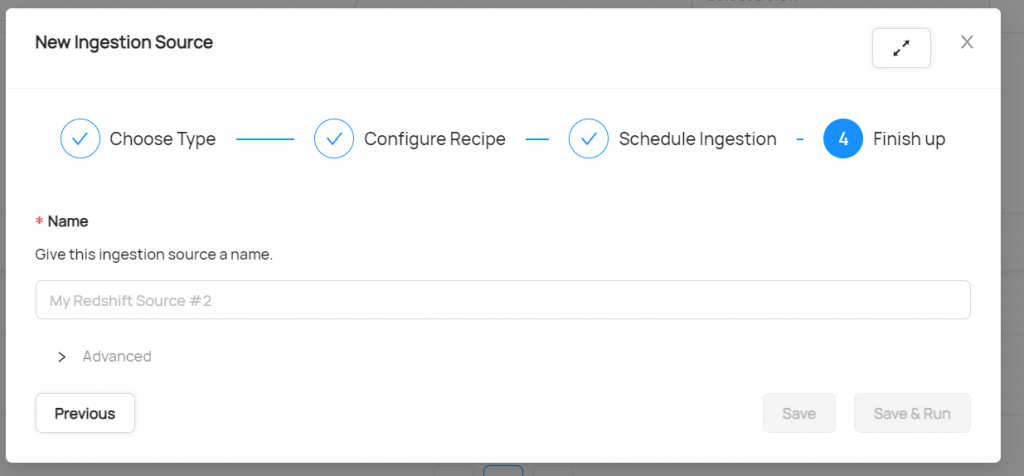
g. The source is created when you click Save. Click Edit to change the configuration and EXECUTE to run the ingestion.
h. After clicking EXECUTE, the task will be executed immediately. if a schedule task is configured, the import will be automatically triggered when the scheduling condition is met. Last Status will show the execution status of the last ingestion.
i. Click the + at the beginning of each source to expand and view the execution records corresponding to the source. If the status is Failed, you can check the logs with the DETAILS button.
Ingest via Command Line
a. Edit the config file and upload that to your datahub server
Check https://datahubproject.io/docs/generated/ingestion/sources/mysql/#cli-based-ingestion for the config structure.
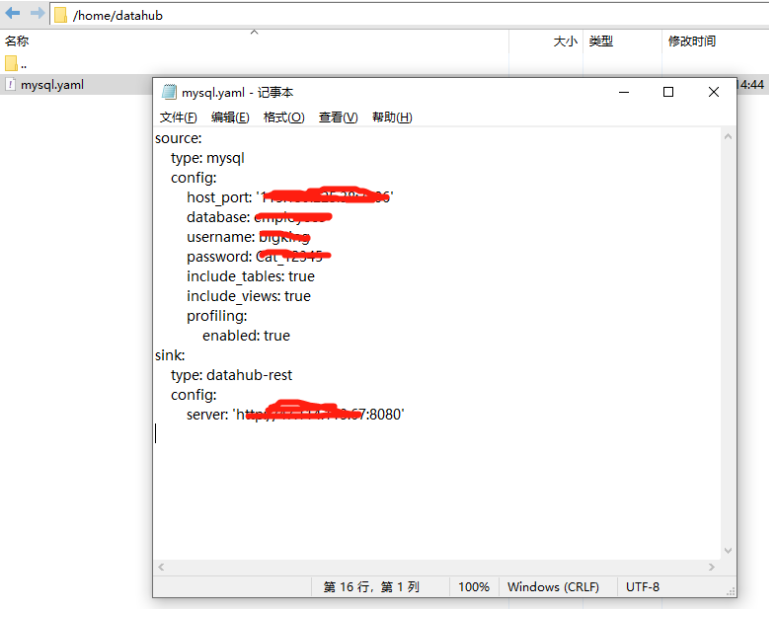
b. Run the following command to read the config file
datahub ingest -c /home/datahub/mssql.yaml