

How to use grabit to analyze the data lineage in mysql database?
Grabit is a helper tool for collecting SQL scripts and stored procedures from various sources such as databases, revision systems like GitHub, bitbucket, and filesystems, and pushes them to SQLFlow server for analysis and generating metadata and data lineage. Grabit official access address.
Main uses of grabit:
- connect to database: Extracting SQL queries such as creating tables, creating views and stored procedures from databases such as Oracle and SQL Server, and sending them to SQLFlow for analysis.
- connect to the SQLFlow system: Get SQL files from revision systems like Github, Bitbucket, etc. and send to SQLFlow for data lineage.
- search file system: Find the SQL file in the local file system and push it to SQLFlow to visualize data lineage.
This article introduces how to use grabit to analyze data lineage in a mysql database.
How to configure the grabit environment?
The environment for running grabit needs to be configured with Java 8 and above, and the following information needs to be configured in the system variables. Please pay attention to the replacement installation path of java when deploying:

run grab
Taking the Windows environment as an example, you need to execute start.bat in the grabit installation directory.
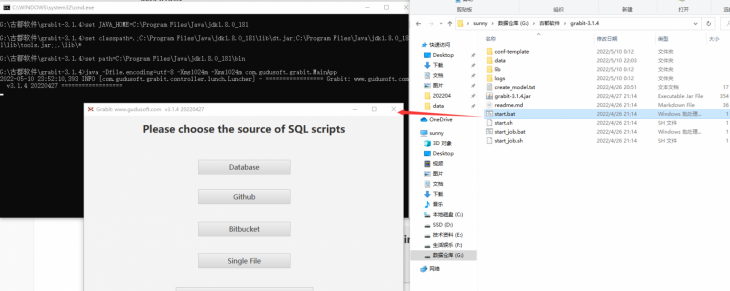
How to connect to the database?
On the grabit startup page, there are various data sources such as Database, Github, Bitbucket, Single File, etc. This article focuses on using the database method to obtain data sources.
For other methods, please refer to here.
Select the mysql database type and click next
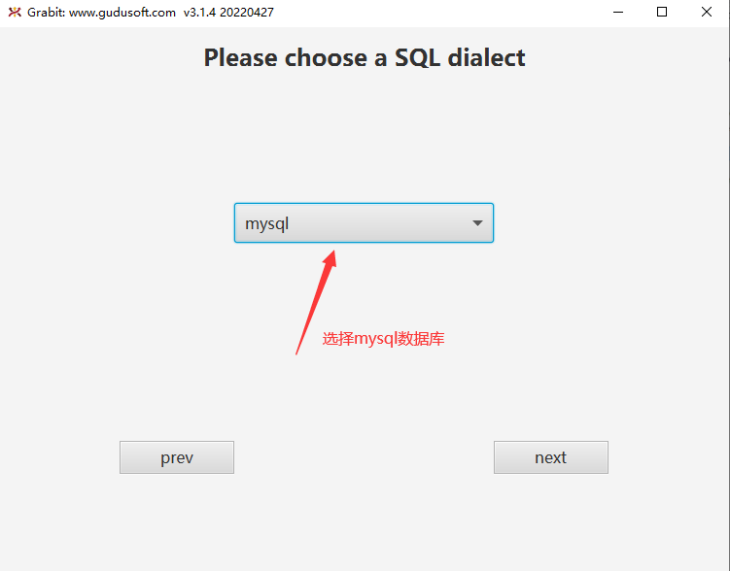
Click next to go to the database configuration information page, where the first four items are required items, and the latter items are optional items. Please refer to here for more detailed information about the specific information in the optional items.
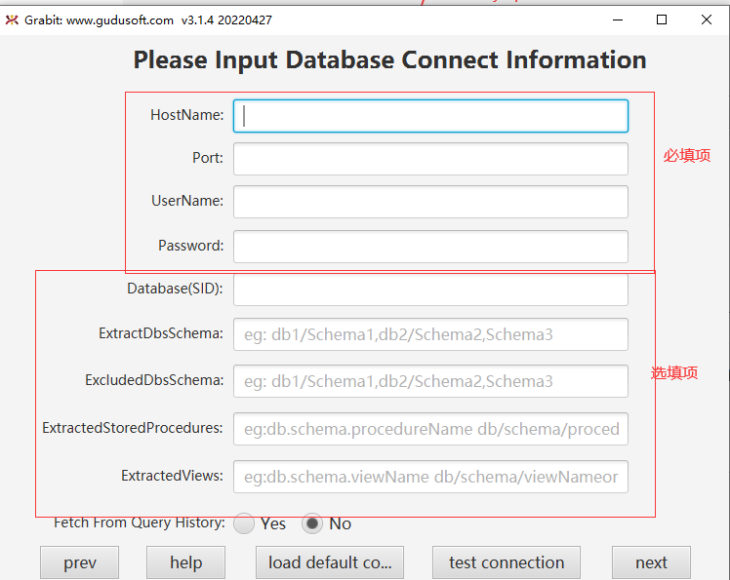
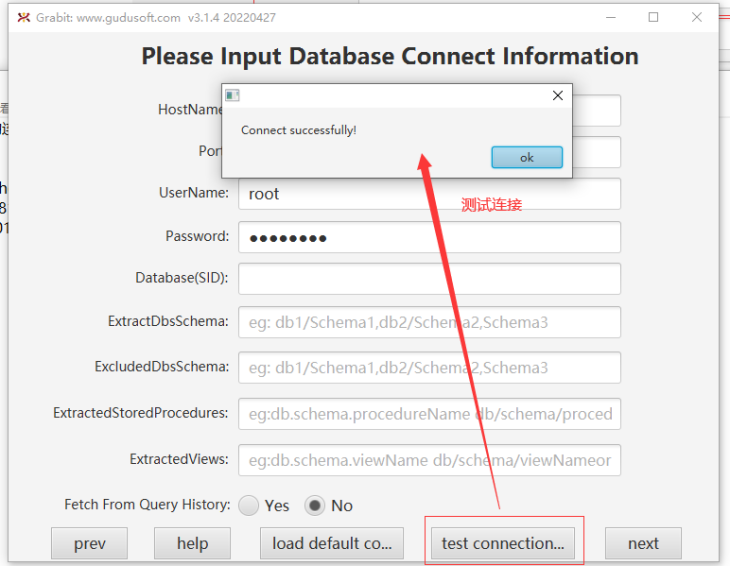

After configuring the above information, click [upload] to upload to the sqlflow server and generate the corresponding job, as shown in the following figure:
If you are using the cloud version of sqlflow, you need to register for a premium membership.
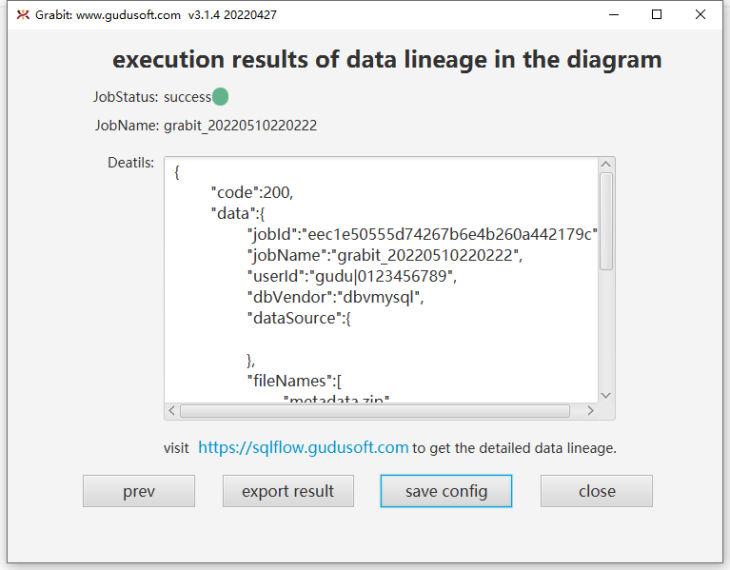
You can click [save config] to save the current configuration file, and then click close to close the grabit.
How to use sqlflow to obtain data lineage analysis results?
You need to check on the sqlflow server. You can see that the corresponding job has been created and can easily obtain the data lineage of automatic analysis, as shown in the following figure:
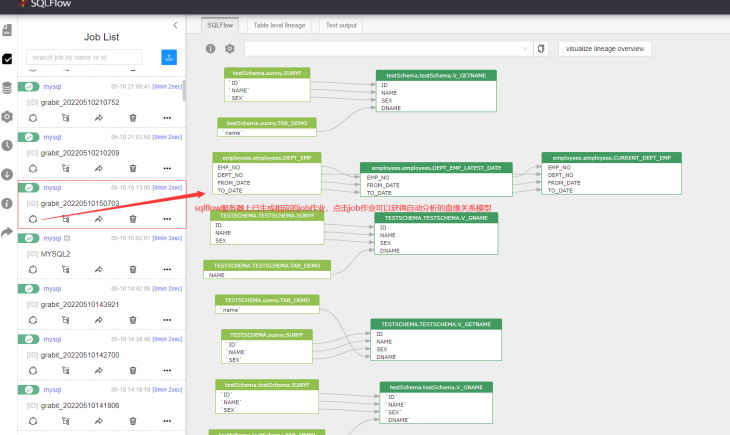
At this point, the introduction of using grabit to analyze the data lineage in the mysql database is completed.
Conclusion
Thank you for reading our article and if you’ve enjoyed it, we would be very happy. If you want to learn more about data lineage, we would like to advise you to visit Gudu SQLFlow for more information. As one of the best data lineage tools, Gudu SQLFlow can not only analyze SQL script files, obtain data lineage, and perform visual display, but also allow users to provide data lineage in CSV format and perform visual display.