Generate data lineage with SQLFlow-Ingester
Why SQLFlow-Ingester?
Gudu SQLFlow supports two kinds of file as the input:
- SQL file, including comments. DDL file for an example, sql such as create table can be used as metadata.
- Json files which contain the database metadata
All other kinds of the input will be no longer supported and users shall convert the inputs to the above two formats. As a result, an out-of-box tool is needed to complete that conversion and automatically submit SQLFlow task.
SQLFlow-Ingester Basic
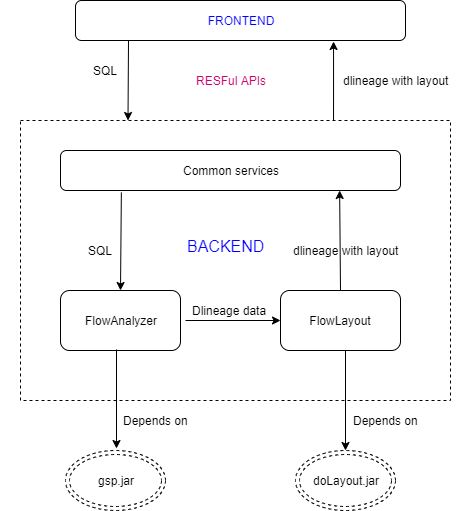
SQLFlow-Ingester is a tool that helps you to extract metadata from various databases and create SQLFlow job based on your database. The extracted metadata file can also be used by dlineage tool to generate data lineage.
SQLFlow-Ingester download address: https://github.com/sqlparser/sqlflow_public/releases
SQLFlow-Ingester has three different parts:
- sqlflow-exporter: getting metadata from database
- sqlflow-extractor: processing raw data files such as log files, various script files (from which SQL statements and metadata to be processed are extracted), CSV files containing SQL statements, etc.
- sqlflow-submitter: submitting sql and metadata to the sqlflow server, creating jobs, generating data lineage, and having the results in the UI.
SQLFlow-Exporter
SQLFlow-exporter is the main functionality of the SQLFlow-Ingester. It can be used to get the metadata from different databases.
SQLFlow-Exporter Usage
Under Linux & Mac:
./exporter.sh -host 127.0.0.1 -port 1521 -db orcl -user scott -pwd tiger -save /tmp/sqlflow-ingester -dbVendor dbvoracleUnder windows:
exporter.bat -host 127.0.0.1 -port 1521 -db orcl -user scott -pwd tiger -save c:\tmp\sqlflow-ingester -dbVendor dbvoracleOr you can directly execute the .jar package, the jar packages are under the ./lib folder:
java -jar sqlflow-exporter-1.0.jar -host 106.54.xx.xx -port 1521 -db orcl -user username -pwd password -save d:/ -dbVendor dbvoracleA metadata.json file will be generated after the success export of metadta from the database.
Example for the success output:
exporter metadata success: <-save>/metadata.json
Parameters
-dbVendor: Database type. Use colon to split dbVendor and version if specific version is required. (:, such as dbvmysql:5.7)
-host: Database host name (ip address or domain name)
-port: Port number
-db: Database name
-user: User name
-pwd: User password
-save: Destination folder path where we put the exported metadata json file. The exported file will be in name as metadata.json.
-extractedDbsSchemas: Export metadata under the specific schema. Use comma to split if multiple schema required (such as ,). We can use this flag to improve the export performance.
-excludedDbsSchemas: Exclude metadata under the specific schema during the export. Use comma to split if multiple schema required (such as ,). We can use this flag to improve the export performance.
-extractedViews: Export metadata under the specific view. Use comma to split if multiple views required (such as ,). We can use this flag to improve the export performance.
-merge: Merge the metadata results which are exported in different process. Use comma to split files to merge.
Improve Export Performance
Time consumed during the export from database could be very long if the data volume is huge. Following actions are made to improve the Ingester export performance:
- JDBC
fetchsizeis set to 1000 for table and view. For sql of view and process thefetchsizeis set to 500. (check this oracle doc for what is jdbcfetchsize: https://docs.oracle.com/middleware/1212/toplink/TLJPA/q_jdbc_fetch_size.htm#TLJPA647) - Parameters
extractedDbsSchemas,excludedDbsSchemasandextractedViewsare improved for oracle and postgresql. A plan has already been made to improve the implementation of these parameters for other databases.
-merge can be used to merge the metadata results. Use comma to split files to merge. All files under the folder will be merged if the given value is the folder path.
exporter.bat -dbVendor dbvpostgresql -extractedDbsSchemas kingland.dbt%,kingland.pub% -host 115.159.225.38 -port 5432 -db kingland -user bigking -pwd Cat_*** -save D:/out/1.json
exporter.bat -dbVendor dbvpostgresql -extractedDbsSchemas kingland.sqlflow -host 115.159.225.38 -port 5432 -db kingland -user bigking -pwd Cat_*** -save D:/out/2.json
exporter.bat -merge D:/out/1.json,D:/out/2.json -save D:/out/merge.json
or
exporter.bat -merge D:/out/ -save D:/out/merge.jsonSQLFlow-Submitter
After decompressing the package, you will find submitter.bat for Windows and submitter.sh for Linux & Mac.
bash submitter.sh -f <path_to_config_file>
note:
path_to_config_file: the full path to the config file
eg:
bash submitter.sh -f /home/workspace/gudu_ingester/submitter_config.jsonUnder Windows:
submitter.bat -f D:/mssql-winuser-config.json
After successfully executing the Submitter, check the Job list on UI and you will find the job submitted by the Submitter, with the Job name configured in the configuration file.
Cron Job
If you are on Linux or Mac, you can schedule the submitter with crontab to create a cron job.
crontab -eIn the editor opened by the above command, let’s say now we want to schedule a daily cron job, add the following code:
0 0 * * * bash submitter.sh -f <path_to_config_file> <lib_path>
note:
path_to_config_file: config file path
lib_path: lib directory absolute pathPlease check this document for more information about cron and you can learn the cron grammar with Wikipedia.
SQLFlow-Submitter Log
The logs of the submitter are persisted under log folder.